LinkedIn hallucination rates
Did OpenAI optimise for the wrong thing? 🤔
A lot of people have noticed ChatGPT not performing according to expectations lately. Simple chat queries like "should I take my car to the car wash that is a 5 minute walk away" get a confident "no, it's a waste". More valuable tasks like financial modelling or reviewing legal contracts come back with subtle errors delivered in the same confident tone. Meanwhile Anthropic's revenues are skyrocketing, even though the latest model benchmarks of each lab do not look that different.
What's going on?
Hard to say for sure, but one difference in the benchmarks is worth highlighting: how often each model hallucinates, or attempts an answer when it isn't sure.
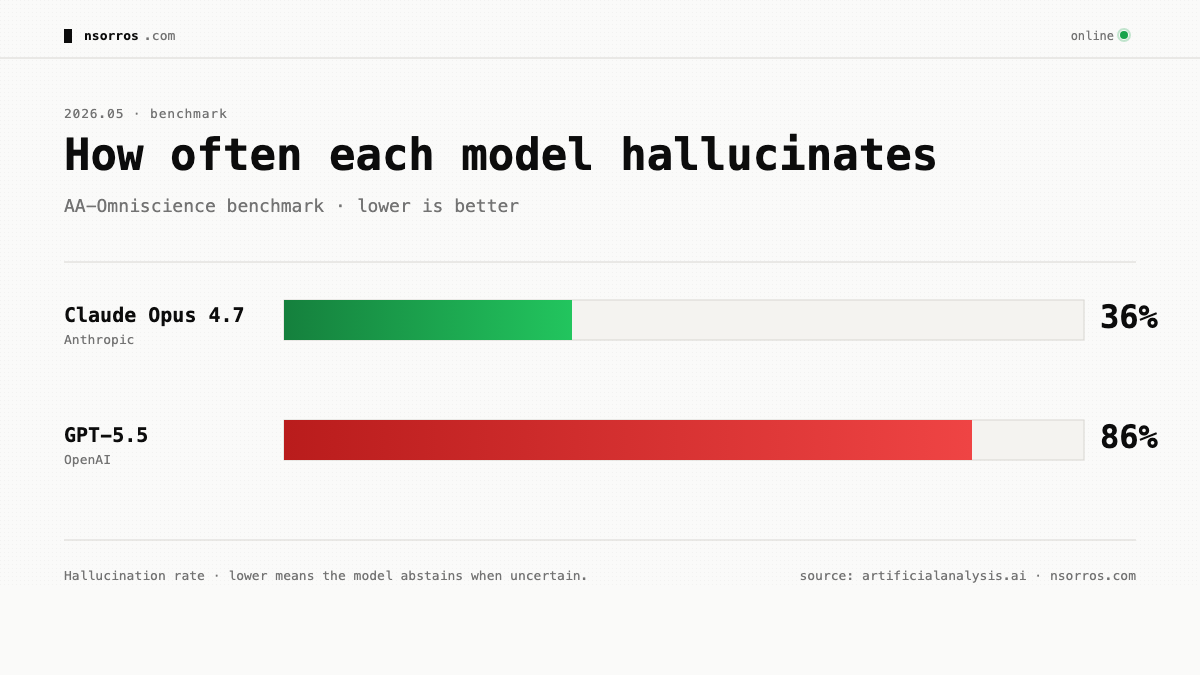
📊 The numbers
On AA-Omniscience, a benchmark that penalises hallucinations and rewards abstention, Claude Opus 4.7 hallucinates 36% of the time. GPT-5.5 hallucinates 86%. On SimpleQA the gap is similarly large. Claude is also better calibrated, and even with extended reasoning, GPT-5.5 delivers wrong answers in the same confident tone as right ones. Anthropic models do this much less.
It is as if the two companies are optimising for different objectives: - OpenAI: get the right answer - Anthropic: do not be wrong, abstain when uncertain
On the surface those look similar, and they produce similar-looking benchmark results. But in real world tasks like coding, financial modelling or law, one wrong reasoning step compounds into a much worse outcome later on.
Which leaves me wondering. Is the Claude Code frenzy a story less about Anthropic going after enterprise and OpenAI after consumers, and more about Anthropic having made a better decision — to build a reliable, calibrated model that turns out to perform better on the tasks that actually matter?