Contextual retrieval and late chunking
💬 Improve RAG by providing context
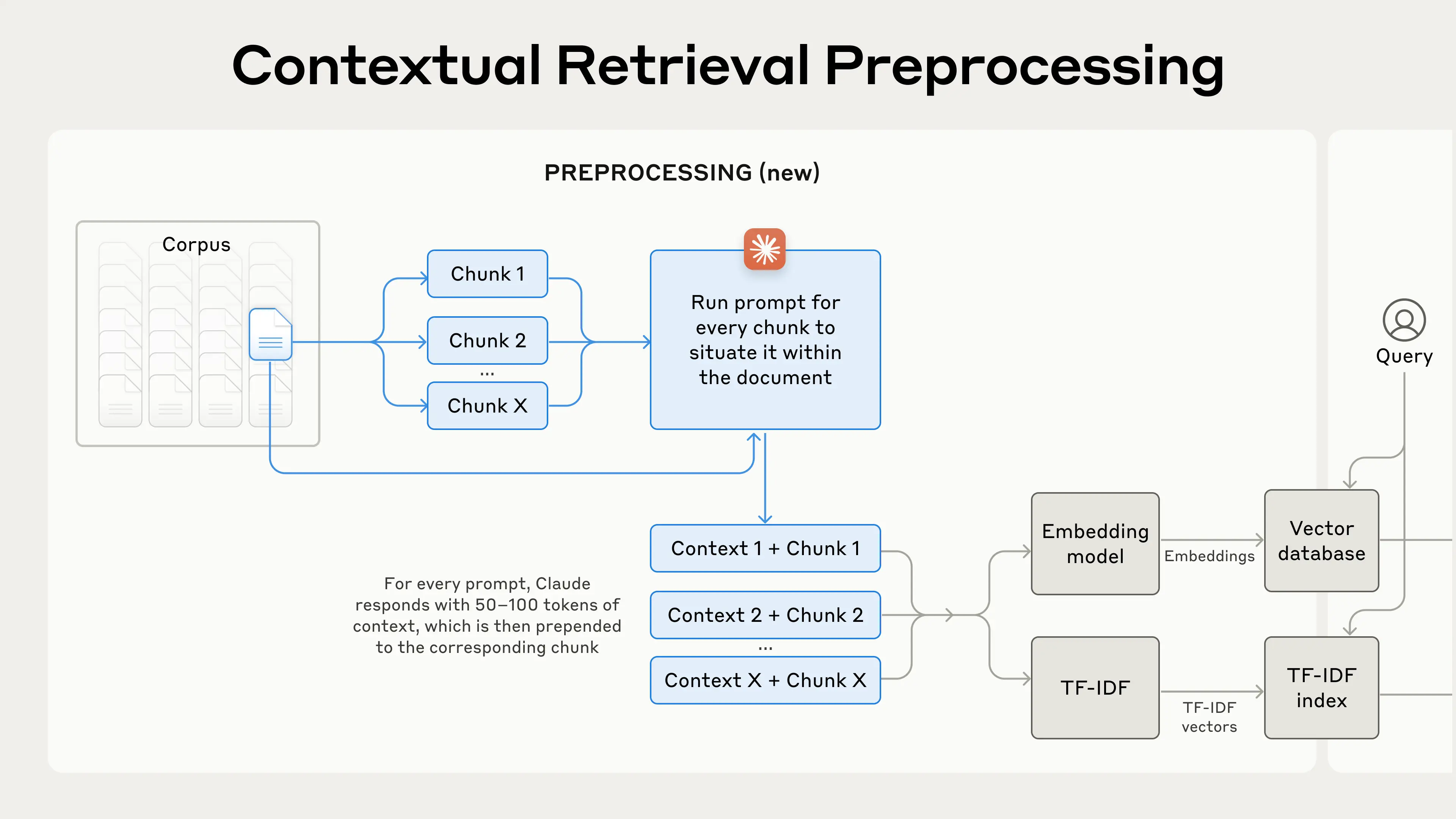
The first step of a RAG solution is splitting ✂️ the information into chunks which are then embedded and stored for retrieval. This splitting process has the undesired effect that the chunk's context is lost, something that often negatively affects the performance 📉
One way to resolve this issue is by asking the LLM to produce the missing context, essentially a summary of what comes before or after, so that the chunk can be more accurately interpreted during retrieval. https://www.anthropic.com/news/contextual-retrieval
Another way to address this is by embedding each token of a document separately, a process that produces contextual embeddings, and only combining them into a chunk embedding later. This preserves the context semantics. https://weaviate.io/blog/late-chunking